informer机制中的本地存储(local cache),对应的结构体是下面的cache struct。
type cache struct {
// cacheStorage bears the burden of thread safety for the cache
cacheStorage ThreadSafeStore
// keyFunc is used to make the key for objects stored in and retrieved from items, and
// should be deterministic.
keyFunc KeyFunc
}该结构体包含有一个KeyFunc函数属性(一个cache对象,或者说一个indexer,或者说一个本地存储,只有一个KeyFunc,作用是为items的value:obj生成对应的key,这里的KeyFunc和下面的IndexFunc不一样,别搞混了)和ThreadSafeStore接口,下面的threadSafeMap struct实现了ThreadSafeStore接口的所有方法。
KeyFunc函数的作用是算出一个obj对象的不重复的key,将算出的key作为items的key,obj作为items的value。而items map就是实际的存储本地存储数据的地方。
type threadSafeMap struct {
lock sync.RWMutex
items map[string]interface{}
// index implements the indexing functionality
index *storeIndex
}type storeIndex struct {
// indexers maps a name to an IndexFunc
indexers Indexers
// indices maps a name to an Index
indices Indices
}在进入threadSafeMap结构体中的storeIndex结构体前,需要了解几个概念。
storeIndex是items map的索引,且设计的比较精妙,但是理解起来有点绕,下面的图是索引的简单例子。接下来的索引的代码要结合下面的图理解会清晰很多。
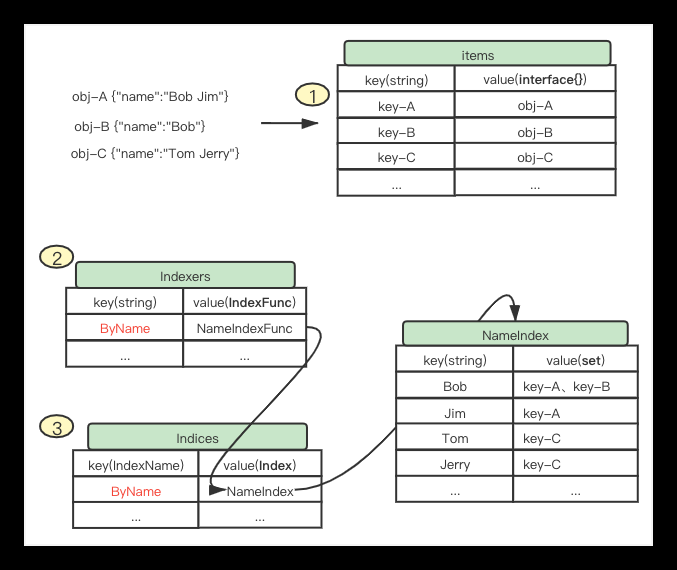
在local store中最主要的是有4个概念需要理解:
- Indexers: type Indexers map[string]IndexFunc
- IndexFunc: type IndexFunc func(obj interface{}) ([]string, error)
- Indices: type Indices map[string]Index
- Index: type Index map[string]sets.String
结合上面的图理解:
- Indexers:索引函数的集合,它为一个map,其key为索引器的名字IndexName(自定义,但要唯一),value为对应的索引函数IndexFunc
- IndexFunc: 索引函数,它接收一个obj,并实现逻辑来取出/算出该obj的索引数组。需要注意是索引数组,具体取什么或算出什么作为索引完全是我们可以自定义的。
- Indices: 索引数据集合,它为一个map,其key和Indexers中的key对应,表示索引器的名字。Value为当前到达数据通过该索引函数计算出来的Index。
- Index: 索引与数据key集合,它的key为索引器计算出来的索引数组中的每一项,value为对应的资源的key(默认namespace/name)集合。
通读下client-go\tools\cache 包下的 store.go 和 thread_safe_store.go 的代码,其中索引有点绕,多次反复对照上图可以获得更好理解。再结合下面实际的建立和查询索引的例子更加有助理解代码:
package main
import (
"fmt"
v1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/api/meta"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/tools/cache"
)
const (
NamespaceIndexName = "namespace"
NodeNameIndexName = "nodeName"
)
func NamespaceIndexFunc(obj interface{}) ([]string, error) {
m, err := meta.Accessor(obj)
if err != nil {
return []string{""}, fmt.Errorf("object has no meta: %v", err)
}
return []string{m.GetNamespace()}, nil
}
func NodeNameIndexFunc(obj interface{}) ([]string, error) {
pod, ok := obj.(*v1.Pod)
if !ok {
return []string{}, nil
}
return []string{pod.Spec.NodeName}, nil
}
func main() {
index := cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{
NamespaceIndexName: NamespaceIndexFunc,
NodeNameIndexName: NodeNameIndexFunc,
})
pod1 := &v1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: "index-pod-1",
Namespace: "default",
},
Spec: v1.PodSpec{NodeName: "node1"},
}
pod2 := &v1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: "index-pod-2",
Namespace: "default",
},
Spec: v1.PodSpec{NodeName: "node2"},
}
pod3 := &v1.Pod{
ObjectMeta: metav1.ObjectMeta{
Name: "index-pod-3",
Namespace: "kube-system",
},
Spec: v1.PodSpec{NodeName: "node2"},
}
_ = index.Add(pod1)
_ = index.Add(pod2)
_ = index.Add(pod3)
// ByIndex 两个参数:IndexName(索引器名称)和 indexKey(需要检索的key)
pods, err := index.ByIndex(NamespaceIndexName, "default")
if err != nil {
panic(err)
}
for _, pod := range pods {
fmt.Println(pod.(*v1.Pod).Name)
}
fmt.Println("==========================")
pods, err = index.ByIndex(NodeNameIndexName, "node2")
if err != nil {
panic(err)
}
for _, pod := range pods {
fmt.Println(pod.(*v1.Pod).Name)
}
}上面的代码可以说是最常见的最简单的索引example。创建了两个索引函数,分别是NamespaceIndexFunc和NodeNameIndexFunc,函数的作用分别是获取obj的namespace信息和获取obj的所在节点信息。创建了3个pod,其中pod1,pod2在default namespace中,pod3在另一个namespace中;pod2,pod3在node2上,pod1在另一个node上。
index.ByIndex是通过索引查找,调用了两次,分别查找default namespace的pod对象 和 在node2节点的pod对象。
GOROOT=C:\go\go1.19 #gosetup
GOPATH=C:\Users\hanwei\go #gosetup
C:\go\go1.19\bin\go.exe build -o C:\Users\hanwei\AppData\Local\Temp\GoLand\___11go_build_lab.exe lab #gosetup
C:\Users\hanwei\AppData\Local\Temp\GoLand\___11go_build_lab.exe
index-pod-1
index-pod-2
==========================
index-pod-2
index-pod-3
Process finished with the exit code 0ByIndex(indexName, indexedValue string) ([]interface{}, error)ByIndex 方法主要工作是:根据索引器名称,比如上面main方法例子中的nodeName索引器名称,获取索引函数NodeNameIndexFunc,所根据索引器名称获得的索引函数为nil,则往上层报错索引器不存在。并通过map indices(map indices的key是索引器名称,value是index)根据索引器名称nodeName获取真正的索引index,index对应上图的右下角的表格,ByIndex 方法的第二个参数对应上图右下角表格的第一列,set := index[indexedValue]中的set对应第二列,set对应items的key值,items map是实际存储obj的map。通过set对应items的key值可以获取实际的obj,即main方法中的pod list。
// ByIndex returns a list of the items whose indexed values in the given index include the given indexed value
func (c *threadSafeMap) ByIndex(indexName, indexedValue string) ([]interface{}, error) {
c.lock.RLock()
defer c.lock.RUnlock()
indexFunc := c.indexers[indexName]
if indexFunc == nil {
return nil, fmt.Errorf("Index with name %s does not exist", indexName)
}
index := c.indices[indexName]
set := index[indexedValue]
list := make([]interface{}, 0, set.Len())
for key := range set {
list = append(list, c.items[key])
}
return list, nil
}_ = index.Add(pod1)
_ = index.Add(pod2)
_ = index.Add(pod3)index.Add的方法是对obj对象建立索引。上面的main方法对三个pod对象创建索引。注意,在对obj创建索引之前需要先创建索引器,否则会报错。也可换一种说法,在创建索引器的时候会检查items是否为空,若不为空会报错。
// Add inserts an item into the cache.
func (c *cache) Add(obj interface{}) error {
key, err := c.keyFunc(obj)
if err != nil {
return KeyError{obj, err}
}
c.cacheStorage.Add(key, obj)
return nil
}index.Add 先通过KeyFunc算出obj的key,然后将key/value对存入items中。并调用c.cacheStorage.Add方法,该方法会调用 updateIndices 方法。
func (c *threadSafeMap) Add(key string, obj interface{}) {
c.Update(key, obj)
}
func (c *threadSafeMap) Update(key string, obj interface{}) {
c.lock.Lock()
defer c.lock.Unlock()
oldObject := c.items[key]
c.items[key] = obj
c.updateIndices(oldObject, obj, key)
}updateIndices中的oldObj为nil(以main方法为例),下面的代码主要处理的工作是:
- 遍历所有indexers,获得key/value对,即索引器名称和索引函数,用索引函数算出obj的indexValues,那上面的main方法中的 nodeName索引器名称,获取索引函数NodeNameIndexFunc 这一对map indexers的key/value对举例,indexValues, err = indexFunc(newObj)这句代码算出三个pod的所在节点。
- 执行 c.addKeyToIndex(key, value, index) 这一句代码。三个参数分别为:第一个参数为 pod obj的存储在items map中的key值,第二个参数为pod obj的pod所在节点的信息,第三个参数为index map,即上图右下角的表格。
- addKeyToIndex方法的就是更新index map,index map的key是对应的上面的node信息,key对应的value是pod obj的item中的key值。
func (c *threadSafeMap) updateIndices(oldObj interface{}, newObj interface{}, key string) {
var oldIndexValues, indexValues []string
var err error
for name, indexFunc := range c.indexers {
if oldObj != nil {
oldIndexValues, err = indexFunc(oldObj)
} else {
oldIndexValues = oldIndexValues[:0]
}
if err != nil {
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))
}
if newObj != nil {
indexValues, err = indexFunc(newObj)
} else {
indexValues = indexValues[:0]
}
if err != nil {
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))
}
index := c.indices[name]
if index == nil {
index = Index{}
c.indices[name] = index
}
if len(indexValues) == 1 && len(oldIndexValues) == 1 && indexValues[0] == oldIndexValues[0] {
// We optimize for the most common case where indexFunc returns a single value which has not been changed
continue
}
for _, value := range oldIndexValues {
c.deleteKeyFromIndex(key, value, index)
}
for _, value := range indexValues {
c.addKeyToIndex(key, value, index)
}
}
}func (c *threadSafeMap) addKeyToIndex(key, indexValue string, index Index) {
set := index[indexValue]
if set == nil {
set = sets.String{}
index[indexValue] = set
}
set.Insert(key)
}总结下,上面的main方法生成的索引相关的map如下:
# Indexers 就是包含的所有索引器(分类)以及对应实现
indexers: {
"namespace": NamespaceIndexFunc,
"nodeName": NodeNameIndexFunc,
}
# Indices 就是包含的所有索引分类中所有的索引数据
indices: {
"namespace": { #namespace 这个索引分类下的所有索引数据
"default": ["pod-1", "pod-2"], # Index 就是一个索引键下所有的对象键列表
"kube-system": ["pod-3"] # Index
},
"nodeName": { # nodeName 这个索引分类下的所有索引数据(对象键列表)
"node1": ["pod-1"], # Index
"node2": ["pod-2", "pod-3"] # Index
}
}- 这两个map 的 key 数量和 名称完全一致。 key是索引器名称,value分别是索引器函数和index map。
- map indices的value也是map,是index map。
- map index 的key/value是 map Indexers的value函数 通过入参obj算出来后插入的。
- mapindex 的value不是的obj,而是 map items 中的key,通过map items[key]可以获取obj。
增删改查索引的实现都挺简单的,其实主要还是要对 indices、indexs 这些数据结构非常了解,这样就非常容易了。
主要难点就是 indices、indexs 这些数据结构,另外还有几个次要的点,不要概念搞混了,indexFunc,keyFunc,items。可以将 indexFunc 当成当前对象的命名空间来看待,对理解又有一定的帮助。
通过索引的设计,可以看出极大加快了查询obj的速度,并且可以自定义索引函数,实现快速个性化索引查询。数据库查询为了加快查询速度也会有索引的设计,上面也可以算是个数据库索引的本地存储的实现。
理解了上面的主线代码,理解任何informer 的 local cache的代码都容易理解了。比如下面Index 函数已经很好理解了,虽然是所有代码中剩下的最复杂的方法了:
Index 函数就是获取一个指定对象的指定索引下面的所有的对象全部获取到,比如我们要获取一个 Pod 所在命名空间下面的所有 Pod,如果更抽象一点,就是符合对象某些特征的所有对象。
// Index returns a list of items that match the given object on the index function.
// Index is thread-safe so long as you treat all items as immutable.
func (c *threadSafeMap) Index(indexName string, obj interface{}) ([]interface{}, error) {
c.lock.RLock()
defer c.lock.RUnlock()
indexFunc := c.indexers[indexName]
if indexFunc == nil {
return nil, fmt.Errorf("Index with name %s does not exist", indexName)
}
indexedValues, err := indexFunc(obj)
if err != nil {
return nil, err
}
index := c.indices[indexName]
var storeKeySet sets.String
if len(indexedValues) == 1 {
// In majority of cases, there is exactly one value matching.
// Optimize the most common path - deduping is not needed here.
storeKeySet = index[indexedValues[0]]
} else {
// Need to de-dupe the return list.
// Since multiple keys are allowed, this can happen.
storeKeySet = sets.String{}
for _, indexedValue := range indexedValues {
for key := range index[indexedValue] {
storeKeySet.Insert(key)
}
}
}
list := make([]interface{}, 0, storeKeySet.Len())
for storeKey := range storeKeySet {
list = append(list, c.items[storeKey])
}
return list, nil
}转载请注明来源,欢迎指出任何有错误或不够清晰的表达。可以邮件至 backendcloud@gmail.com

