Trie树简介
前缀树即Trie树。
下图为 b,abc,abd,bcd,abcd,efg,hii 这7个单词创建的trie树。
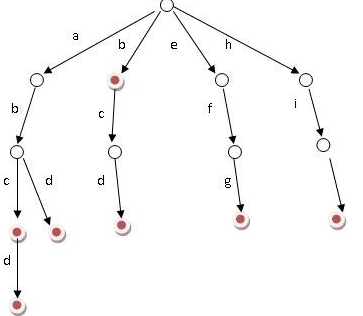
上图从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
除根节点外,每一个节点只包含一个字符。
每个节点的所有子节点包含的字符都不相同。
相比较map/hash字典实现的优点:利用字符串公共前缀来减少查询时间,减少无谓的字符串比较。
http router 是什么
从功能上来讲,就是 URI → handler 函数的映射。
web框架中的快速路由Trie树
Trie树的结构非常适用于路由匹配。不同的web框架中的快速路由用到了不同的路由算法。Trie 树是其中简单的一种。
因为现在web框架中的路由往往加入了动态路由功能,即加入了参数提取,通配符,这些功能简化了用户的路由注册,但是增加了Trie树实现路由的复杂度。
比如定义了如下路由规则:
- /:lang/doc
- /:lang/tutorial
- /:lang/intro
- /about
- /p/blog
- /p/related
用前缀树来表示,是这样的: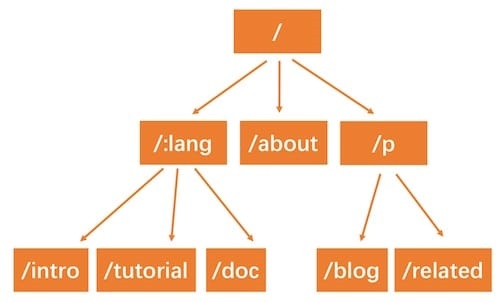
动态路由具备以下两个功能。
- 参数匹配:。例如 /p/:lang/doc,可以匹配 /p/c/doc 和 /p/go/doc。
- 通配*。例如 /static/*filepath,可以匹配/static/fav.ico,也可以匹配/static/js/jQuery.js,这种模式常用于静态服务器,能够递归地匹配子路径。
golang实现
本次分析的源码放在 https://github.com/geektutu/7days-golang/blob/master/gee-web/day7-panic-recover/gee/router.go 和 https://github.com/geektutu/7days-golang/blob/master/gee-web/day7-panic-recover/gee/trie.go
首先要设计上图树的节点的结构体,用于存储一些节点信息:
type node struct {
pattern string // 待匹配路由,例如 /p/:lang 相当于完整的URL,但是会根据场景置空
part string // 路由中的一部分URL片段
children []*node // 子节点,例如 [doc, tutorial, intro]
isWild bool // 是否精确匹配,part 含有 : 或 * 时为true 和trie树无关,为了http动态路由特别增加的字段
}
// roots key eg, roots['GET'] roots['POST']
// handlers key eg, handlers['GET-/p/:lang/doc'], handlers['POST-/p/book']
// route结构体的构造函数
func newRouter() *router {
return &router{
roots: make(map[string]*node),
handlers: make(map[string]HandlerFunc),
}
}
type router struct {
roots map[string]*node // roots 来存储每种请求方式(key是GET/POST/DELETE/PUT等,value是节点)的Trie 树根节点
handlers map[string]HandlerFunc //handlers的key是 请求的method + 连接符 + 完整URL,value是对应的处理函数
}
// 路由的结构体的设计是为了将 Trie 树应用到路由中。不用Trie,用map/hash实现的路由,即URL作为key,request method + URL 对应的处理函数作为value。路由算法主要包括路由注册和路由发现两个部分:
路由注册
路由注册的过程包括两部分:
- 检查路由根节点(以request method GET/POST/DELETE/PUT 区分几个路由根结点)是否存在,不存在则新建。并注册根节点信息。
- 递归注册根节点的所有子节点信息。
func (r *router) addRoute(method string, pattern string, handler HandlerFunc) {
parts := parsePattern(pattern)
key := method + "-" + pattern
_, ok := r.roots[method]
if !ok {
r.roots[method] = &node{}
}
r.roots[method].insert(pattern, parts, 0)
r.handlers[key] = handler
}
// 入参 height: 节点的层数,顶层root是0,每下一层+1
// node结构体的patten成员变量,只有当该node已经是最底层的时候,才会赋值为完整的URL,否则为空
// 查找子节点,若找不到则新建子节点(赋值两个变量:part(当前处理的URL片段)和isWild(是否检测到冒号和星号动态路由标志))并将子节点放入结构体的子节点成员变量中
// 递归对子节点做相同(本身函数)的操作
func (n *node) insert(pattern string, parts []string, height int) {
if len(parts) == height {
n.pattern = pattern
return
}
part := parts[height]
child := n.matchChild(part)
if child == nil {
child = &node{part: part, isWild: part[0] == ':' || part[0] == '*'}
n.children = append(n.children, child)
}
child.insert(pattern, parts, height+1)
}
// 根节点node结构体的成员变量part是空的,子节点的part变量是URL片段。或者理解成当前node结构体的处理函数的入参parts []string和height int组合获取的part是提供给子节点的。或者理解成第一个URL的片段是提供给第二层(height=1),并非第一层(height=0)的node的part。参考上图的黄色方块的白色内容。
// 第一个匹配成功的子节点
func (n *node) matchChild(part string) *node {
for _, child := range n.children {
if child.part == part || child.isWild {
return child
}
}
return nil
}路由发现
路由注册的过程包括两部分:
- 一层层查找到最底层匹配的节点
- 获取动态路由(冒号,星号)匹配的参数
// 返回值*node是找到最底层匹配的节点,nil表示未找到
// 返回值params的数据类型是map[string]string,key/value是提取的动态路由(冒号,星号)匹配的参数和值
func (r *router) getRoute(method string, path string) (*node, map[string]string) {
searchParts := parsePattern(path)
params := make(map[string]string)
root, ok := r.roots[method]
// 查找不到以方法名区分的根节点,返回未查到
if !ok {
return nil, nil
}
// 找到以方法名区分的根节点,调用递归函数search(), 具体的步骤可以参考路由注册,这里不详细说了。区别主要是注册只要找到一个匹配的子节点,因为注册只会注册一条线,而路由发现和走迷宫一样,需要并行多条线查找合适的路径,和路由注册只匹配一个子节点,会走入死胡同。
n := root.search(searchParts, 0)
// 如找到最底层的节点,即路由发现,则提取动态路由的参数和值
if n != nil {
parts := parsePattern(n.pattern)
for index, part := range parts {
if part[0] == ':' {
params[part[1:]] = searchParts[index]
}
if part[0] == '*' && len(part) > 1 {
params[part[1:]] = strings.Join(searchParts[index:], "/")
break
}
}
return n, params
}
//路由发现未找到匹配路由
return nil, nil
}
// 递归查找
func (n *node) search(parts []string, height int) *node {
if len(parts) == height || strings.HasPrefix(n.part, "*") {
if n.pattern == "" {
return nil
}
return n
}
part := parts[height]
children := n.matchChildren(part)
for _, child := range children {
result := child.search(parts, height+1)
if result != nil {
return result
}
}
return nil
}
// 所有匹配成功的节点
func (n *node) matchChildren(part string) []*node {
nodes := make([]*node, 0)
for _, child := range n.children {
if child.part == part || child.isWild {
nodes = append(nodes, child)
}
}
return nodes
}路由注册和路由发现的共通方法 func parsePattern() []string
该方法就是将入参完整的URL用斜杠分隔成字符串数组。同时考虑了两种情况:
- 连续斜杠的合并(适用于和路由组和URL拼接的重复情况)
- 通配符,但只支持一个,因为*通配符就是匹配当前和后面的所有URL,只需要考虑1个星的情况
// Only one * is allowed
func parsePattern(pattern string) []string {
vs := strings.Split(pattern, "/")
parts := make([]string, 0)
for _, item := range vs {
if item != "" {
parts = append(parts, item)
if item[0] == '*' {
break
}
}
}
return parts
}转载请注明来源,欢迎指出任何有错误或不够清晰的表达。可以邮件至 backendcloud@gmail.com

