一般的linux都是GPOS(通用)内核。GPOS是不保证实时的,但是对于大多数应用程序来说是没有问题的。GPOS可以充分利用物理资源。但在实时性要求性比较高的场景需要使用实时内核,RT内核。RT的代价就是牺牲掉了资源利用率,使得相同的资源生产能力下降。
安装实时内核
yum安装后,重启系统
# yum install kernel-rt -y
# systemctl reboot
启动选项中选择RT内核,进入实时内核
实时内核PREEMPT-RT主要的特性
- 完全内核抢占。
- 自旋锁可抢占。
- 高进度时钟。引入高精度时钟。高精度内核提供了更高的时钟精度,可以为实时系统提供更细粒度的时间控制。
- Priority inheritance protocol。
- 中断线程化。
设置时钟源为HPET
处理器系统例如NUMA或者SMP架构的一般都会支持多个时钟源,在系统启动阶段内核会自动发现可用的时钟源并选择一个,例如查看当前系统支持的时钟源命令如下:
# cat /sys/devices/system/clocksource/clocksource0/available_clocksource
tsc hpet acpi_pm
所以在上面例子中,时钟源可以选择TSC、HPET以及ACPI_PM。查看当前系统使用的时钟源命令如下:
# cat /sys/devices/system/clocksource/clocksource0/current_clocksource
tsc
设置时钟源为HPET
# echo hpet > /sys/devices/system/clocksource/clocksource0/current_clocksource
自旋锁可抢占
自旋锁是一个互斥设备,它只有两个值:“锁定”和“解锁”。它通常实现为某个整数值中的某个位。希望获得某个特定锁得代码测试相关的位。如果锁可用,则“锁定”被设置,而代码继续进入临界区;相反,如果锁被其他人获得,则代码进入忙循环(而不是休眠,这也是自旋锁和一般锁的区别)并重复检查这个锁,直到该锁可用为止,这就是自旋的过程。
自旋锁有几个重要的特性:1、被自旋锁保护的临界区代码执行时不能进入休眠。2、被自旋锁保护的临界区代码执行时是不能被被其他中断中断。3、被自旋锁保护的临界区代码执行时,内核不能被抢占。从这几个特性可以归纳出一个共性:被自旋锁保护的临界区代码执行时,它不能因为任何原因放弃处理器。
在普通内核中,自旋锁保护的临界区不可被抢占。如果当前自旋锁被持有,那么其他线程再获取自旋锁的时候,就会进入忙等状态。实时内核中,用rtmutexes实现了自旋锁,自旋锁保护的代码区域是可被抢占的。
什么是中断
Linux 内核需要对连接到计算机上的所有硬件设备进行管理,毫无疑问这是它的份内事。如果要管理这些设备,首先得和它们互相通信才行,一般有两种方案可实现这种功能:
- 轮询(polling) 让内核定期对设备的状态进行查询,然后做出相应的处理;
- 中断(interrupt) 让硬件在需要的时候向内核发出信号(变内核主动为硬件主动)。
第一种方案会让内核做不少的无用功,因为轮询总会周期性的重复执行,大量地耗用 CPU 时间,因此效率及其低下,所以一般都是采用第二种方案 。
从物理学的角度看,中断是一种电信号,由硬件设备产生,并直接送入中断控制器(如 8259A)的输入引脚上,然后再由中断控制器向处理器发送相应的信号。处理器一经检测到该信号,便中断自己当前正在处理的工作,转而去处理中断。此后,处理器会通知 OS 已经产生中断。这样,OS 就可以对这个中断进行适当的处理。不同的设备对应的中断不同,而每个中断都通过一个唯一的数字标识,这些值通常被称为中断请求线。
中断线程化
标准内核中,中断具有最高优先级,可以无条件抢占当前任务,而且中断来临的时机以及执行的时间长短都是未知的,这样就会影响系统线程的执行时间,使得系统的处理增加了不确定因素,导致无法满足实时性的要求。
实时内核将中断的处理过程线程化,中断处理程序不是在单独的中断上下文中执行,而是由内核线程处理中断请求。中断执行过程受到线程调度策略控制,与其他线程公平竞争处理器资源,可以被抢占。
中断线程化流程的分析
下面将对中断线程化进行简要分析。
在初始化阶段,中断线程化的中断初始化与常规中断初始化大体上相同,在 start_kernel() 函数中都调用了 trap_init() 和 init_IRQ() 两个函数来初始化 irq_desc_t 结构体,不同点主要体现在内核初始化创建 init 线程时,中断线程化的中断在 init() 函数中还将调用 init_hardirqs(kernel/irq/manage.c(已经打过上文提到的补丁)),来为每一个 IRQ 创建一个内核线程,最高实时优先级为 50,依次类推直到 25,因此任何 IRQ 线程的最低实时优先级为 25。
void __init init_hardirqs(void)
{
……
for (i = 0; i < NR_IRQS; i++) {
irq_desc_t *desc = irq_desc + i;
if (desc->action && !(desc->status & IRQ_NODELAY))
desc->thread = kthread_create(do_irqd, desc, "IRQ %d", irq);
……
}
}
static int do_irqd(void * __desc)
{
……
/*
* Scale irq thread priorities from prio 50 to prio 25
*/
param.sched_priority = curr_irq_prio;
if (param.sched_priority > 25)
curr_irq_prio = param.sched_priority - 1;
……
}如果某个中断号状态位中的 IRQ_NODELAY 被置位,那么该中断不能被线程化。
在中断处理阶段,两者之间的异同点主要体现在:两者相同的部分是当发生中断时,CPU 将调用 do_IRQ() 函数来处理相应的中断,do_IRQ() 在做了必要的相关处理之后调用 __do_IRQ()。两者最大的不同点体现在 __do_IRQ() 函数中,在该函数中,将判断该中断是否已经被线程化(如果中断描述符的状态字段不包含 IRQ_NODELAY 标志,则说明该中断被线程化了),对于没有线程化的中断,将直接调用 handle_IRQ_event() 函数来处理。
fastcall notrace unsigned int __do_IRQ(unsigned int irq, struct pt_regs *regs)
{
……
if (redirect_hardirq(desc))
goto out_no_end;
……
action_ret = handle_IRQ_event(irq, regs, action);
……
}
int redirect_hardirq(struct irq_desc *desc)
{
……
if (!hardirq_preemption || (desc->status & IRQ_NODELAY) || !desc->thread)
return 0;
……
if (desc->thread && desc->thread->state != TASK_RUNNING)
wake_up_process(desc->thread);
……
}对于已经线程化的情况,调用 wake_up_process() 函数唤醒中断处理线程,并开始运行,内核线程将调用 do_hardirq() 来处理相应的中断,该函数将判断是否有中断需要被处理,如果有就调用 handle_IRQ_event() 来处理。handle_IRQ_event() 将直接调用相应的中断处理函数来完成中断处理。
不难看出,不管是线程化还是非线程化的中断,最终都会执行 handle_IRQ_event() 函数来调用相应的中断处理函数,只是线程化的中断处理函数是在内核线程中执行的。
并不是所有的中断都可以被线程化,比如时钟中断,主要用来维护系统时间以及定时器等,其中定时器是操作系统的脉搏,一旦被线程化,就有可能被挂起,这样后果将不堪设想,所以不应当被线程化。如果某个中断需要被实时处理,它可以像时钟中断那样,用 SA_NODELAY 标志来声明自己非线程化,例如:
static struct irqaction irq0 = {
timer_interrupt, SA_INTERRUPT | SA_NODELAY, CPU_MASK_NONE, "timer", NULL, NULL
};其中,SA_NODELAY 到 IRQ_NODELAY 之间的转换,是在 setup_irq() 函数中完成的。
irqbalance
irqbalance是一个linux的实用程序,它主要是用于分发中断请求到CPU核心上,有助于性能的提升。它的目的是寻求省电和性能优化之间的平衡。
irqbalance用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于 Performance mode 或 Power-save mode。处于Performance mode 时,irqbalance 会将中断尽可能均匀地分发给各个 CPU core,以充分利用 CPU 多核,提升性能。
处于Power-save mode 时,irqbalance 会将中断集中分配给第一个 CPU,以保证其它空闲 CPU 的睡眠时间,降低能耗。
irqbalance根据系统中断负载的情况,自动迁移中断保持中断的平衡,同时会考虑到省电因素等等。 但是在实时系统中会导致中断自动漂移,对性能造成不稳定因素,在高性能的场合建议关闭并设置IRQs的CPU亲和性。
设置IRQs的CPU亲和性
1. 查看/proc/interrupts文件确认每个设备的中断号(IRQs)。
2. 如果需要设定某个中断至绑定到一个CPU上,直接将CPU掩码写入/proc/irq/[number]/smp_affinity,例如将48号中断绑定到CPU 0:
# echo 1 > /proc/irq/48/smp_affinity
3. 设定在下一次中断产生时才会生效,中断产生时可以观察到已绑定CPU那一栏的中断次数在增加。
irqbalance流程分析
//irqbalance.c
int main(int argc, char** argv)
{
/* ... */
while (keep_going) {
sleep_approx(SLEEP_INTERVAL); //#define SLEEP_INTERVAL 10
/* ... */
clear_work_stats();
parse_proc_interrupts();
parse_proc_stat();
/* ... */
calculate_placement();
activate_mappings();
/* ... */
}
/* ... */
}从程序的主循环可以很清楚的看到它的逻辑,在退出之前每隔10秒它做了以下的几个事情:
- 清除统计
- 分析中断的情况
- 分析中断的负载情况
- 根据负载情况计算如何平衡中断
- 实施中断亲缘性变更
下面简要分析下这五个过程的几个关键过程,用简要的shell脚本翻译原来的c语言代码
分析中断的情况
$cat>x.sh
SYSDEV_DIR="/sys/bus/pci/devices/"
for dev in `ls $SYSDEV_DIR`
do
IRQ=`cat $SYSDEV_DIR$dev/irq`
CLASS=$(((`cat $SYSDEV_DIR$dev/class`)>>16))
printf "irq %s: class[%s] " $IRQ $CLASS
if [ -f "/proc/irq/$IRQ/affinity_hint" ]; then
printf "affinity_hint[%s] " `cat /proc/irq/$IRQ/affinity_hint`
fi
if [ -f "$SYSDEV_DIR$dev/local_cpus" ]; then
printf "local_cpus[%s] " `cat $SYSDEV_DIR$dev/local_cpus`
fi
if [ -f "$SYSDEV_DIR$dev/numa_node" ]; then
printf "numa_node[%s]" `cat $SYSDEV_DIR$dev/numa_node`
fi
echo
done
$chmod +x x.sh
$./x.sh|grep 98
irq 98: class[2] local_cpus[00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000]简单的分析下数字:class_codes[2]=IRQ_ETH 也就是说这个中断是块网卡。
分析中断的负载情况
$ grep cpu015/proc/stat
cpu15 30068830 85841 22995655 3212064899 536154 91145 2789328 0
第7,8项分别对应着中断和软中断的次数,二者加起来就是我们所谓的CPU负载。
实施中断亲缘性变更
echo MASK > /proc/irq/N/smp_affinity
测试
测试工具
Cyclictest是rt-tests 下使用最广泛的测试工具,一般主要用来测试使用内核的延迟,从而判断内核的实时性。判断标准:延迟响应时间(us)
测试方法
对GPOS和RTOS分别执行下面的命令:
# taskset -c 2 stress --cpu 1 --io 1 -d 1
# taskset -c 2 cyclictest -m -n -q -p95 -D 12h -h60 -i 200 > cyclictest_non_12hour.out
测试结果
汇总整理两边的测试结果数据,利用gnuplot工具画图进行对比分析,对比图如下:
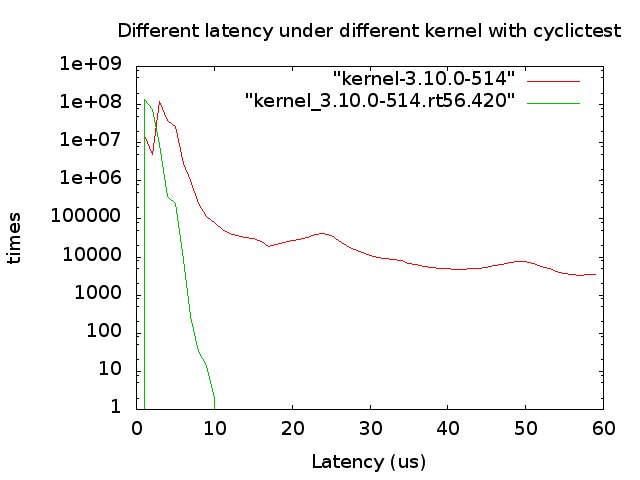
在12小时cyclictest测试后,实时内核最高延迟为10微秒,远远低于普通内核的2279微秒,而且普通内核延迟在10微秒至60微秒的次数也远远超过实时内核,所以优化后的实时内核延迟性能数据相对普通内核要稳定,最大门限不超过10微秒,满足系统实时性需求。
转载请注明来源,欢迎指出任何有错误或不够清晰的表达。可以邮件至 backendcloud@gmail.com

